

С момента своего публичного запуска 10 несколько лет назад Twitter использовался в качестве платформы социальных сетей среди друзей, службы обмена мгновенными сообщениями для пользователей смартфонов и рекламного инструмента для корпораций и политиков.
Но это также бесценный источник данных для исследователей и ученых, таких как я, которые хотят изучать, как люди чувствуют себя и функционируют в сложных социальных системах.
Анализируя твиты, мы смогли наблюдать и собирать данные о социальных взаимодействиях миллионов людей «в дикой природе», за пределами контролируемых лабораторных экспериментов.
Это позволило нам разработать инструменты для мониторинга коллективные эмоции больших популяций, Найти самые счастливые места в Соединенных Штатах и многое другое.
Итак, как именно Twitter стал таким уникальным ресурсом для ученых-вычислителей? И что это позволило нам открыть?

Самый большой подарок для исследователей
В июле 15, 2006, Twittr (как было тогда известно) публично запустили как «мобильная услуга, которая помогает группам друзей отказываться от случайных мыслей с помощью SMS». Возможность отправлять бесплатные тексты групп 140-персонажей приводила к тому, что многие ранние пользователи (включая меня) использовали платформу.
Со временем количество пользователей взорванный: от 20 миллионов в 2009 до 200 миллионов в 2012 и 310 миллионах сегодня. Вместо того, чтобы напрямую общаться с друзьями, пользователи просто рассказывали своим последователям, как они себя чувствуют, реагируют на новости положительно или отрицательно или шутит.
Для исследователей самый большой подарок Twitter - предоставление большого количества открытых данных. Twitter был одной из первых крупных социальных сетей для предоставления образцов данных с помощью интерфейса Application Programming Interfaces (API), который позволяет исследователям запрашивать Twitter для определенных типов твитов (например, твиты, содержащие определенные слова), а также информацию о пользователях ,
Это привело к взрыву исследовательских проектов, использующих эти данные. Сегодня поисковая система Google Scholar для «Twitter» производит шесть миллионов обращений, по сравнению с пятью миллионами для «Facebook». Разница особенно бросается в глаза, учитывая, что Facebook имеет примерно в пять раз больше пользователей, чем Twitter (и на два года старше).
Щедрая политика данных Twitter, несомненно, привела к отличной бесплатной рекламе для компании, так как интересные научные исследования были привлечены основными средствами массовой информации.
Изучение счастья и здоровья
Поскольку традиционные данные переписи медленно и дорого собираются, открытые фиды данных, такие как Twitter, могут предоставить окно в режиме реального времени, чтобы увидеть изменения в больших группах населения.
Университет Вермонта Лаборатория вычислительной истории была основана в 2006 и изучает проблемы в прикладной математике, социологии и физике. Начиная с 2008, The Story Lab собрала миллиарды твитов через канал «Gardenhose» Twitter, API, который в реальном времени передает случайную выборку из 10 процентов всех общедоступных твитов.
Я провел три года в Лаборатории вычислительной истории, и мне посчастливилось участвовать во многих интересных исследованиях, использующих эти данные. Например, мы разработали hedonometer который измеряет счастье Twittersphere в реальном времени. Сосредоточив внимание на геолокационных твитах, отправленных с смартфонов, мы смогли карта самые счастливые места в Соединенных Штатах. Возможно, неудивительно, что мы обнаружили Гавайи станут самым счастливым государством и виноделием Напы, самым счастливым городом для 2013.
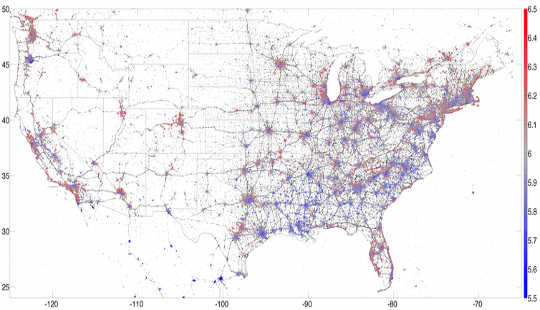 Карта из 13 миллионов размещенных в США твитов из 2013, по цвету от счастья, с красным цветом, указывающим на счастье и синие, указывающие на печаль. PLoS ONE, Предоставил автор.Эти исследования были более глубокими: корреляция использования слова Twitter с демографией помогла нам понять основные социально-экономические модели в городах. Например, мы могли бы связать использование слова с факторами здоровья, такими как ожирение, поэтому мы создали lexicocalorimeter для измерения «калорийности» сообщений в социальных сетях. Твиты из определенного региона, в которых упоминались высококалорийные продукты, увеличивали «калорийность» этого региона, в то время как твиты, которые упомянули упражнения, уменьшили нашу метрику. Мы обнаружили, что эта простая мера коррелирует с другими показателями здоровья и благополучия, Другими словами, твиты смогли дать нам мгновенный снимок общего состояния здоровья города или региона.
Карта из 13 миллионов размещенных в США твитов из 2013, по цвету от счастья, с красным цветом, указывающим на счастье и синие, указывающие на печаль. PLoS ONE, Предоставил автор.Эти исследования были более глубокими: корреляция использования слова Twitter с демографией помогла нам понять основные социально-экономические модели в городах. Например, мы могли бы связать использование слова с факторами здоровья, такими как ожирение, поэтому мы создали lexicocalorimeter для измерения «калорийности» сообщений в социальных сетях. Твиты из определенного региона, в которых упоминались высококалорийные продукты, увеличивали «калорийность» этого региона, в то время как твиты, которые упомянули упражнения, уменьшили нашу метрику. Мы обнаружили, что эта простая мера коррелирует с другими показателями здоровья и благополучия, Другими словами, твиты смогли дать нам мгновенный снимок общего состояния здоровья города или региона.
Используя богатство данных Twitter, мы также смогли видеть повседневные движения людей в беспрецедентных подробностях, Понимание моделей мобильности человека, в свою очередь, способно трансформировать моделирование болезней, открывая новую область цифровая эпидемиология.
В других исследованиях мы рассмотрели, выражают ли путешественники большее счастье в Твиттере, чем те, кто остается дома (ответ: они это делают), и если счастливые люди склонны держаться вместе в социальной сети (опять же, они это делают). В самом деле, положительность, по-видимому, испечена в самом языке, в том смысле, что мы имеем более положительные слова, чем отрицательные слова. Это было не только в Twitter, но и на разных носителях (например, в книгах, фильмах и газетах) и на языках.
Эти исследования - и тысячи других, подобных им со всего мира, были возможны только благодаря Twitter.
В последующие годы 10
Итак, что мы можем ожидать от Twitter в течение следующих 10 лет?
Некоторые из самых интересных работ в настоящее время связаны с подключением данных социальных сетей с помощью математических моделей для прогнозирования явлений на уровне населения, таких как вспышки болезней. У исследователей уже был некоторый успех в увеличении моделей болезней с данными Twitter для прогнозирования гриппа, в частности FluOutlook платформу, разработанную Северо-Восточным университетом и Институтом научного обмена.
Тем не менее, остается ряд проблем. Данные социальных сетей страдают от очень низкого отношения «сигнал-шум». Другими словами, твиты, которые имеют отношение к конкретному исследованию, часто заглушаются неуместным «шумом».
Поэтому мы должны постоянно осознавать, что было названо "большие данные hubris«При разработке новых методов и не слишком самоуверенны в наших результатах. В связи с этим следует стремиться к получению интерпретируемых «стеклянных ящиков» прогнозов из этих данных (в отличие от прогнозов «черного ящика», в которых алгоритм скрыт или не ясен).
Данные социальных сетей часто (справедливо) подвергаются критике за то, что они являются маленькими, нерепрезентативный образец более широкого населения. Одной из основных проблем для исследователей является выяснение того, как учитывать такие перекошенные данные в статистических моделях. В то время как каждый год люди используют социальные сети, мы должны продолжать пытаться понять предубеждения в этих данных. Например, данные по-прежнему имеют тенденцию к избыточному представлению молодых людей за счет пожилых людей.
Только после разработки лучших методов коррекции смещения исследователи смогут сделать полностью уверенные прогнозы из твитов.
Об авторе
Льюис Митчелл, преподаватель прикладной математики, Университет Аделаиды
Эта статья изначально была опубликована в Беседа, Прочтите оригинал статьи.
Книги по этой теме
at Внутренний рынок самовыражения и Amazon




















